Несобственное априорное распределение
●Что если мы вообще ничего не знаем о параметре \(\lambda\) — откуда взять prior? Можно взять «плоский» prior: \(p(\lambda) = 1\) на всей положительной оси. Но он не интегрируется! Это и есть несобственный prior.
Плоский prior \(p(\lambda) \propto 1\) на \((0,\infty)\) говорит: «все значения \(\lambda\) равновероятны». Но \(\int_0^\infty 1\, d\lambda = \infty\) — это не распределение вероятностей. Однако, перемножив на правдоподобие (например, Poisson), получаем posterior, который уже интегрируется. Данные «спасают» анализ.
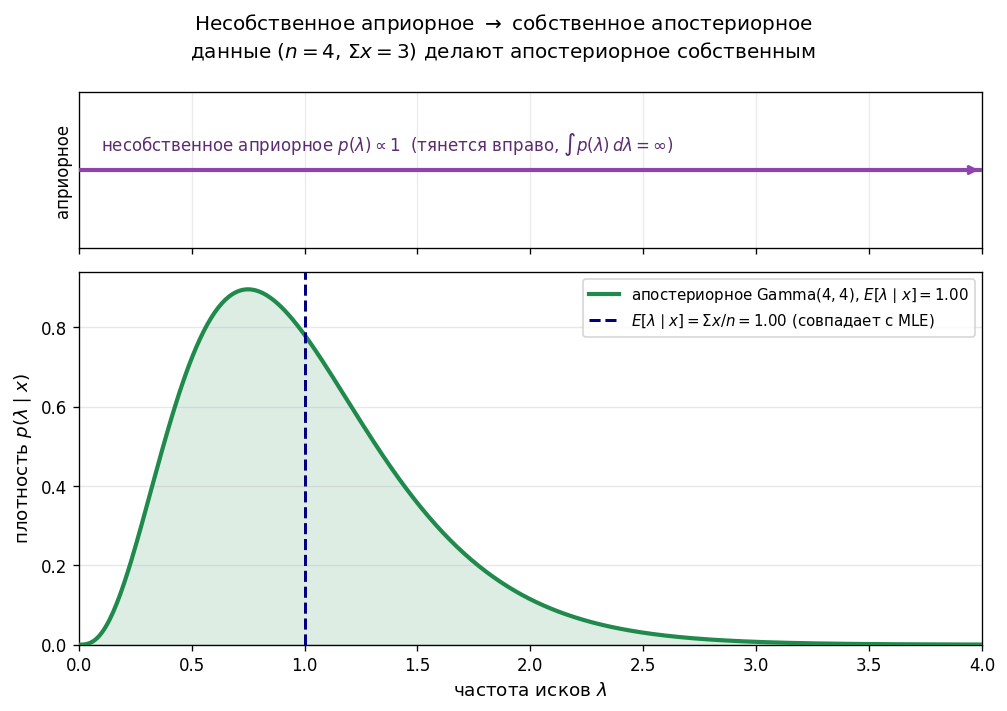
Схема: на оси \(x\) — значения \(\lambda\). Плоская горизонтальная «линия» с подписью «improper prior \(p(\lambda) \propto 1\)» (тянется вправо до бесконечности). Под ней — posterior после данных: нормальный вид, концентрированная кривая. Надпись: «posterior собственный — использование prior допустимо».
✍️ Разберём на числах
Prior: \(p(\lambda) \propto 1\) (несобственный). Данные: \(n=4\) лет, \(\Sigma x=3\). Posterior \(\propto \lambda^3 e^{-4\lambda}\) — это \(\mathrm{Gamma}(4, 4)\), собственное! Оценка: \(E[\lambda \mid x] = 4/4 = 1{,}0 = \Sigma x/n = \text{MLE}\). Improper prior \(\to\) MLE.
📐 Формула
Несобственный prior: \(p(\theta) \geq 0\), но \(\int p(\theta)\, d\theta = \infty\). Условие допустимости: \(\int p(\theta \mid x)\, d\theta = 1\) (posterior собственный). Uninformative prior (Джеффрис): \(p(\lambda) \propto 1\) или \(p(\lambda) \propto 1/\lambda\).