Модель коллективного риска
●Страховая компания обрабатывает тысячи мелких полисов. Вести пополисный учёт дорого — проще рассуждать о «потоке исков»: сколько их придёт и каким будет каждый. Это и есть коллективная модель риска.
Вместо «смотрим на каждый полис» — «смотрим на каждый иск». Случайны: \(N\) — сколько исков поступило (не фиксировано!), и \(X_i\) — размер каждого из них. Предполагаем, что все \(X_i\) одинаково распределены и независимы от \(N\). Это даёт компактную параметризацию: нужно знать только распределение \(N\) и распределение одного \(X\), — полисы не нужны.
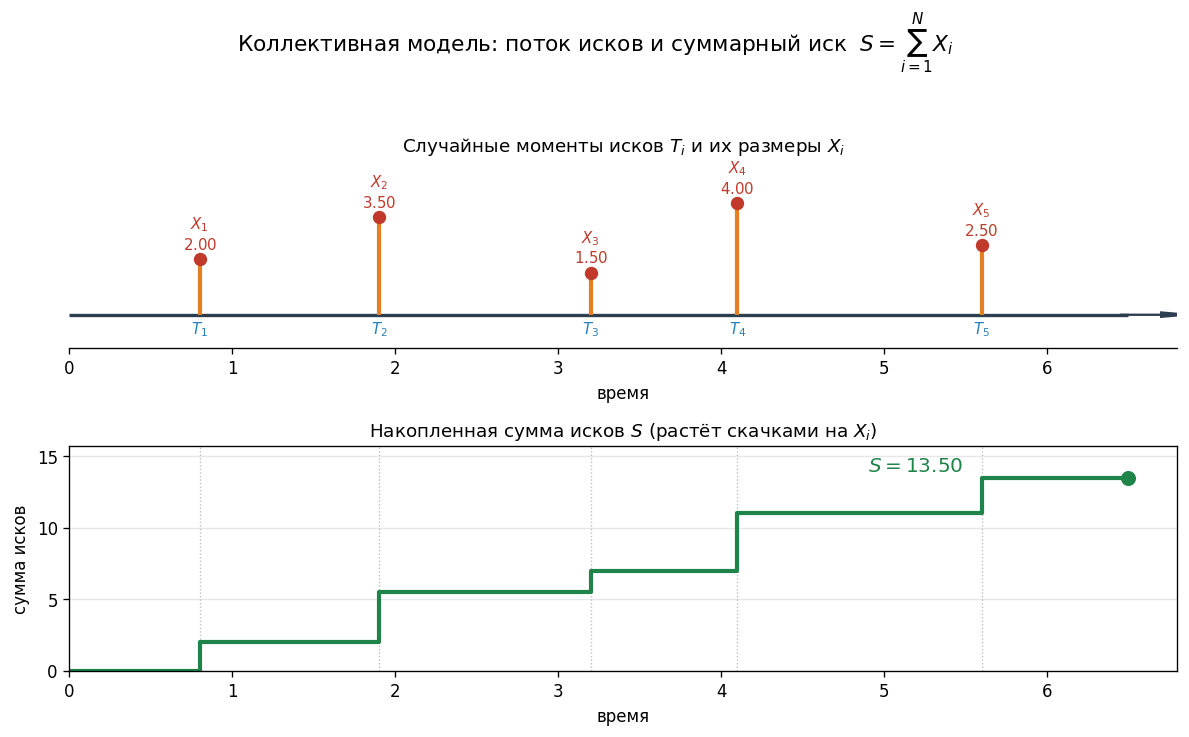
Диаграмма «поток исков»: ось времени → случайные моменты \(T_1\), \(T_2\), … → каждому сопоставлен случайный размер \(X_i\); накопленная сумма — \(S\).
✍️ Разберём на числах
\(N \sim \mathrm{Poisson}(200)\), \(E[X] = 5\) тыс. руб., \(\mathrm{Var}[X] = 10\ (\text{тыс. руб.})^2\). \(E[S] = 200 \cdot 5 = 1000\) тыс. руб. \(\mathrm{Var}[S] = 200 \cdot 10 + 200 \cdot 25 = 2000 + 5000 = 7000\ (\text{тыс. руб.})^2\). При Poisson: \(\mathrm{Var}[N] = E[N] = 200\), поэтому второй член \(= 200 \cdot 5^2 = 5000\).
📐 Формула
\(N\) — случайное число исков, \(X_i\) — i.i.d. размеры, независимы от \(N\). Русск.: коллективная модель. Англ.: collective risk model, compound distribution.